PDF OCR
Creates searchable PDF. It performs text recognition on the image contents of the PDF and makes them searchable. This is one of our premium features. A point to be noted is that the call cost for this action is twice the number of pages in the document. i.e. if OCR is performed on a 5-page document, the call cost would be 10.
Parameters
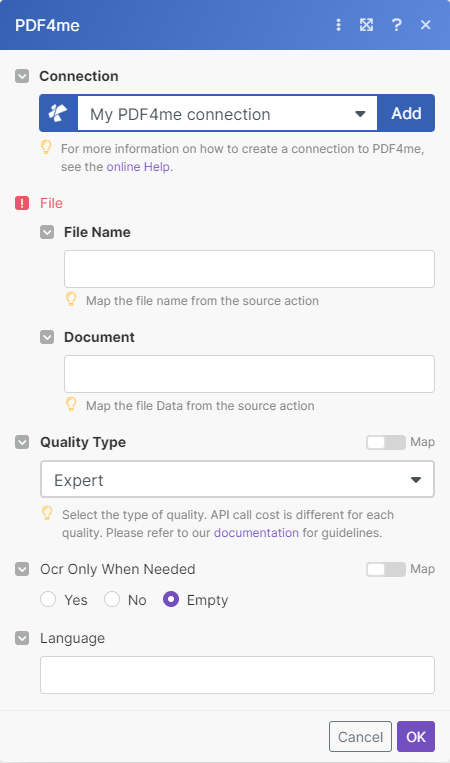
- File NameString, Required
Map the file name from the source action
- DocumentString, Required
Map the file Data from the source action.
- Quality TypeOption, RequiredDefault: Expert
Standard (draft)- Suitable for normal PDFs, consumes 1 API call per file
Expert (high) - Suitable for PDFs generated from Images and scanned documents. Consumes 2 API calls per page
- OCR Only When NeededBooleanDefault: No
Set ‘Yes’ to skip doing recognition if the text is already searchable
- Language CodeString
Specify the language of the text in the source file. Only use if the output is not recognizable
- Is Asyncboolean
You can select any one-
Yes
No
Empty
Output
- NameString
The name of the output file.
- Doc DataBuffer
The output document in Base64 format.