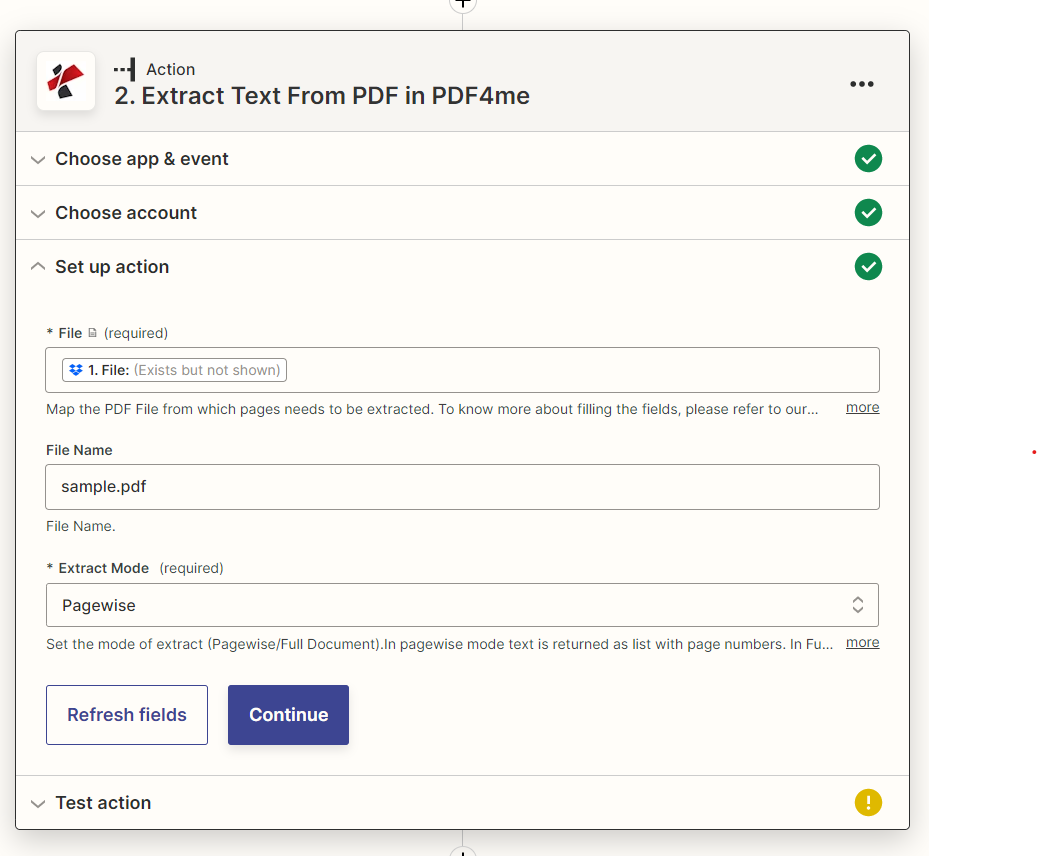
Extract Text from PDF
Extract text from a PDF. Copies all text from your PDF document entirely or page-wise. If you select ‘Extract Mode’ page-wise you will get a list of text with the page number. In ‘Full Document’ mode, you will get the entire document text in a single field.
Parameters
- FileFile, Required
Map the PDF file that contains the text to be extracted. The file uploaded should always be PDF. A URL containing a file can also be passed as a parameter.
- File NameString
You can specify the file name. Otherwise, the name will be picked from the File field.
- Extract ModeOption, RequiredDefault: pagewise
Select the type of extract. The allowed values are
- Full Document: extract the entire document text into the output field ‘text’.
- Page wise: returns a list of text with page numbers. (pageTextInfo output field)
Output
The output contains the extracted text based on the Extract Mode.
- TextString
The document’s entire extracted text will be available in this field if ‘Extract Mode’ is page wise.
- PageTextInfoArray
Contains a list of extracted text with the page numbers. ( If ‘Extract Mode’ is Full Document). List contains the below properties.
PageNumber
PageText