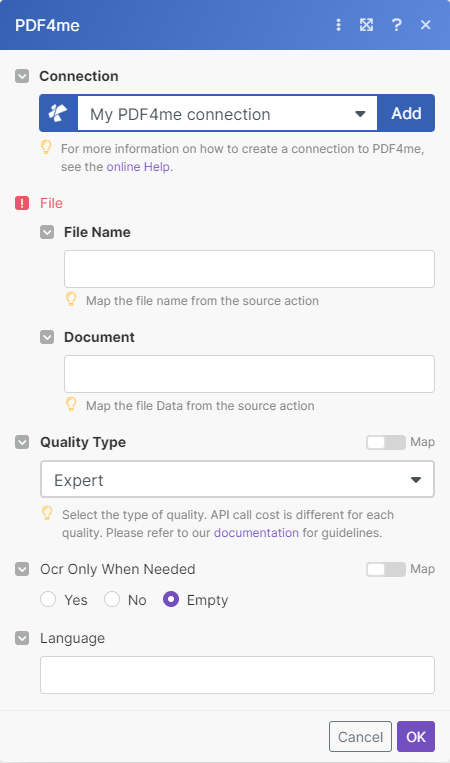
PDF OCR
使用’PDF OCR’操作对 PDF 文档执行 OCR。使用此操作自动对 PDF 文档执行 OCR,无需额外编码。
参数
- 文件String, Required
从源操作映射文件数据以进行 OCR 处理
- 输出文件名String, Required
从源操作映射文件数据。
- 质量类型Option, RequiredDefault: Expert
标准 (草稿) - 适用于普通 PDF,每文件消耗 1 个 API 调用
专家 (高) - 适用于从图像和扫描文档生成的 PDF。每页消耗 2 个 API 调用
- 仅在需要时进行 OCRBooleanDefault: No
设置 ‘是’ 跳过识别,如果文本已可搜索
- 语言代码String
指定源文件中文本的语言。仅在输出不可识别时使用
- 异步boolean
您可以从以下选项中选择一个:
是
否
空
输出
- 名称String
输出文件的名称。
- 文档数据Buffer
输出文档为 Buffer 格式。