按文本拆分PDF
连接器ID:SplitByText
通过在文本内容中搜索特定短语来拆分PDF文档。使用您认为可能唯一的文本来识别需要拆分文档的页面。使用按文本拆分操作创建流程来自动化此过程。
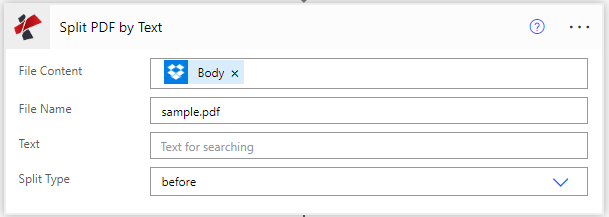
参数
- 文件内容Base64, Required
从上一个操作映射源PDF文件内容
- 文件名String, Required
带有适当文件扩展名的源文件名
- 文本String, Required
用于拆分PDF的文本
- 拆分类型Enum, RequiredDefault: Before
选择拆分方式。
- 之前 - PDF在包含文本的页面之前拆分
- 之后 - PDF在包含文本的页面之后拆分
输出
- 文件内容Binary
来自PDF4me操作的输出文件内容
- 文件名String
来自PDF4me操作的输出文件名